Research

1. Document Understanding
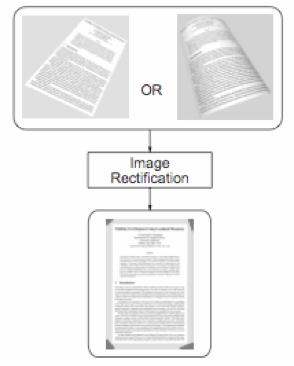
Jian Liang, Daniel DeMenthon and David Doermann, "Geometric Rectification of Camera-captured Document Images", PAMI, vol. 30, no. 4, pp. 591–605, April 2008. (Download PDF)
Compared to typical scanners, handheld cameras offer convenient, flexible, portable, and non-contact image capture, which enables many new applications and breathes new life into existing ones. However, camera-captured documents may suffer from distortions caused by non-planar document shape and perspective projection, which lead to failure of current OCR technologies. We present a geometric rectification framework for restoring the frontal-flat view of a document from a single camera-captured image. Our approach estimates 3D document shape from texture flow information obtained directly from the image without requiring additional 3D/metric data or prior camera calibration. Our framework provides a unified solution for both planar and curved documents and can be applied in many, especially mobile, camera-based document analysis applications. Experiments show that our method produces results that are significantly more OCR compatible than the original images.
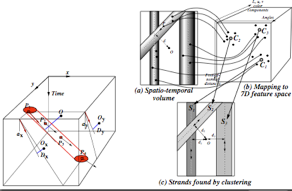
Daniel DeMenthon and David Doermann, "Video Retrieval of Near-Duplicates using k-Nearest Neighbor Retrieval of Spatio-Temporal Descriptors", Multimedia Tools and Applications, pp. 229-253, vol. 30, no. 3, Sept. 2006 (Download PDF)
This paper describes a novel methodology for implementing video search functions such as retrieval of near-duplicate videos and recognition of actions in surveillance video. Videos are divided into half-second clips whose stacked frames produce 3D space-time volumes of pixels. Pixel regions with consistent color and motion properties are extracted from these 3D volumes by a threshold-free hierarchical space-time segmentation technique. Each region is then described by a high-dimensional point whose components represent the position, orientation and, when possible, color of the region. In the indexing phase for a video database, these points are assigned labels that specify their video clip of origin. All the labeled points for all the clips are stored into a single binary tree for efficient k-nearest neighbor retrieval. The retrieval phase uses video segments as queries. Half-second clips of these queries are again segmented by space-time segmentation to produce sets of points, and for each point the labels of its nearest neighbors are retrieved. The labels that receive the largest numbers of votes correspond to the database clips that are the most similar to the query video segment. We illustrate this approach for video indexing and retrieval and for action recognition. First, we describe retrieval experiments for dynamic logos, and for video queries that differ from the indexed broadcasts by the addition of large overlays. Then we describe experiments in which office actions (such as pulling and closing drawers, taking and storing items, picking up and putting down a phone) are recognized. Color information is ignored to insure independence of action recognition to people's appearance. One of the distinct advantages of using this approach for action recognition is that there is no need for detection or recognition of body parts.
2. Indexing and Retrieval of MPEG Video

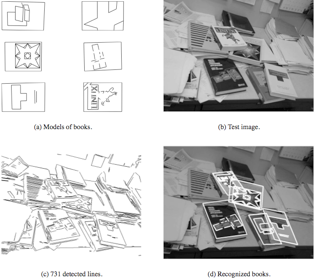
Philip David and Daniel DeMenthon, "Object Recognition in High Clutter Images Using Line Features", ICCV 2005, Beijing, October 2005 (Download PDF).
Philip David and Daniel DeMenthon, "Object Recognition by Deterministic Annealing of Ranked Affine Pose Hypotheses", University of Maryland Technical Report LAMP-TR-123, CAR-TR-1010, CS-TR-4731, UMIACS-TR-2005-38, July 2005. (Download pdf)
We present an object recognition algorithm that uses model and image line features to locate complex objects in high clutter environments. Finding correspondences between model and image features is the main challenge in most object recognition systems. In our approach, corresponding line features are determined by a three-stage process. The first stage generates a large number of approximate pose hypotheses from correspondences of one or two lines in the model and image. Next, the pose hypotheses from the previous stage are quickly ranked by comparing local image neighborhoods to the corresponding local model neighborhoods. Fast nearest neighbor and range search algorithms are used to implement a distance measure that is unaffected by clutter and partial occlusion. The ranking of pose hypotheses is invariant to changes in image scale, orientation, and partially invariant to affine distortion. Finally, a robust pose estimation algorithm is applied for refinement and verification, starting from the few best approximate poses produced by the previous stages. Experiments on real images demonstrate robust recognition of partially occluded objects in very high clutter environments.
3. Object Recognition
Philip David, Daniel DeMenthon, Ramani Duraiswami and Hanan Samet, "SoftPOSIT: Simultaneous Pose and Correspondence Determination", International Journal of Computer Vision, 59, No. 3, September-October 2004, pp. 259-284. (Download PDF).
The problem of pose estimation arises in many areas of computer vision, including object recognition, object tracking, site inspection and updating, and autonomous navigation using scene models. We present a new algorithm, called SoftPOSIT, for determining the pose of a 3D object from a single 2D image in the case that correspondences between model points and image points are unknown. The algorithm combines Gold's iterative SoftAssign algorithm for computing correspondences and DeMenthon's iterative POSIT algorithm for computing object pose under a full-perspective camera model. Our algorithm, unlike most previous algorithms for this problem, does not have to hypothesize small sets of matches and then verify the remaining image points. Instead, all possible matches are treated identically throughout the search for an optimal pose. The performance of the algorithm is extensively evaluated in Monte Carlo simulations on synthetic data under a variety of levels of clutter, occlusion, and image noise. These tests show that the algorithm performs well in a variety of difficult scenarios, and empirical evidence suggests that the algorithm has a run-time complexity that is better than previous methods by a factor equal to the number of image points. The algorithm is being applied to the practical problem of autonomous vehicle navigation in a city through registration of 3D architectural models of buildings to images obtained from an on-board camera.
4. Model Based Object Pose
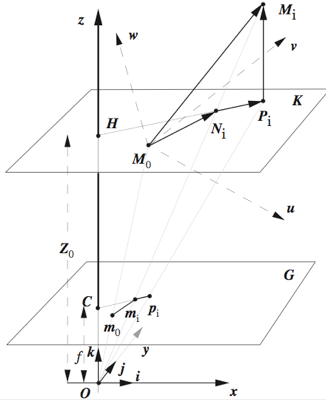
D. DeMenthon and L.S. Davis, "Model-Based Object Pose in 25 Lines of Code", International Journal of Computer Vision, 15, pp. 123-141, June 1995 (Download PDF).
We describe a method for finding the pose of an object from a single image. We assume that we can detect and match in the image four or more noncoplanar feature points of the object, and that we know their relative geometry on the object. The method combines two algorithms; the first algorithm, POS (Pose from Orthography and Scaling) approximates the perspective projection with a scaled orthographic projection and finds the rotation matrix and the translation vector of the object by solving a linear system; the second algorithm, POSIT (POS with ITerations), uses in its iteration loop the approximate pose found by POS in order to compute better scaled orthographic projections of the feature points, then applies POS to these projections instead of the original image projections. POSIT converges to accurate pose measurements in a few iterations. POSIT can be used with many feature points at once for added insensitivity to measurement errors and image noise. Compared to classic approaches making use of Newton's method, POSIT does not require starting from an initial guess, and computes the pose using an order of magnitude fewer floating point operations; it may therefore be a useful alternative for real-time operation. When speed is not an issue, POSIT can be written in 25 lines or less in Mathematica; the code is provided in an Appendix.
Updated August 2009